15 Feb 2017
|
gradle
Gradle에 대해서 공부한 내용을 요약한 포스팅입니다.
Gradle 이란?
보통 Maven의 장점과 Ant의 장점을 합쳐 놓은 빌드 툴로 불리우는데 XML대신 Groovy DSL로 작성되어 라인수가 훨씬 적고 task단위로 만들어 실행 할 수 있으며 개발자가 필요한 빌드로직을 조합하여 사용 가능합니다. 그리고 Gradle Wrapper를 사용하여 Gradle이 설치되지 않은 환경에서도 빌드 가능합니다.
설치방법
Gradle 수동설치 링크에서 Install 설치파일을 다운받아 풀고 GRADLE_HOME, 실행파일 경로를 PATH에 잡아주면 됩니다.
추가로 윈도우 환경에서 UTF-8 빌드환경을 만들기 위해 아래와 같이 GRADLE_OPTS을 설정합니다.
GRADLE_OPTS="-Dfile.encoding=UTF-8"
초기화하기(cmd)
명령어를 통해 gradle을 초기화 하는 방법은 아래와 같습니다.
$ gradle init --type java-library
type값은 basic, java-library, pom, groovy-library, scala-library가 있습니다.
위와 같이 실행하면 gradle의 기본 설정 생성과 함께 src 기본폴더가 생성됩니다.(자세한 구조는 아래 IDE에서…)
초기화하기(IntelliJ)
- Gradle타입의 새 프로젝트를 선택하고 Next를 클릭합니다.
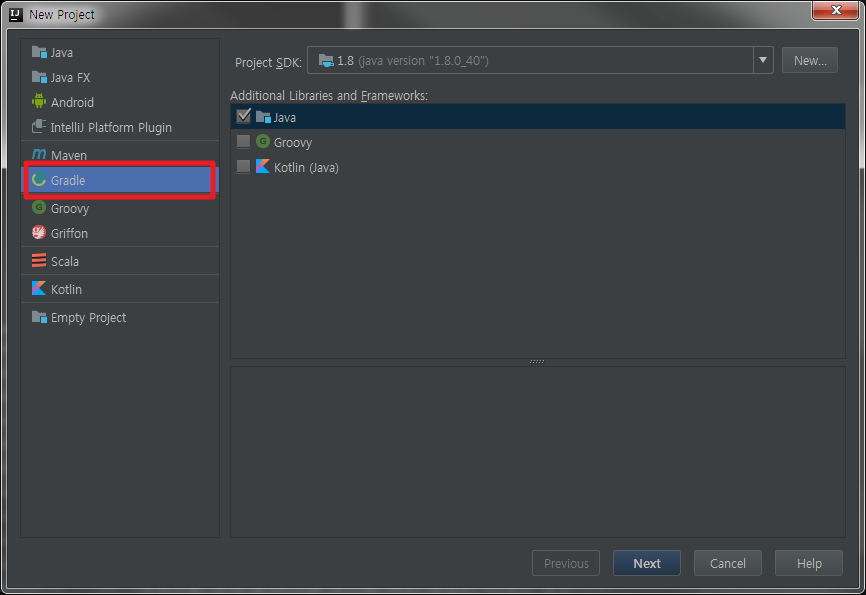
- GroupId, ArtifactId를 선택하고 Next를 클릭합니다.
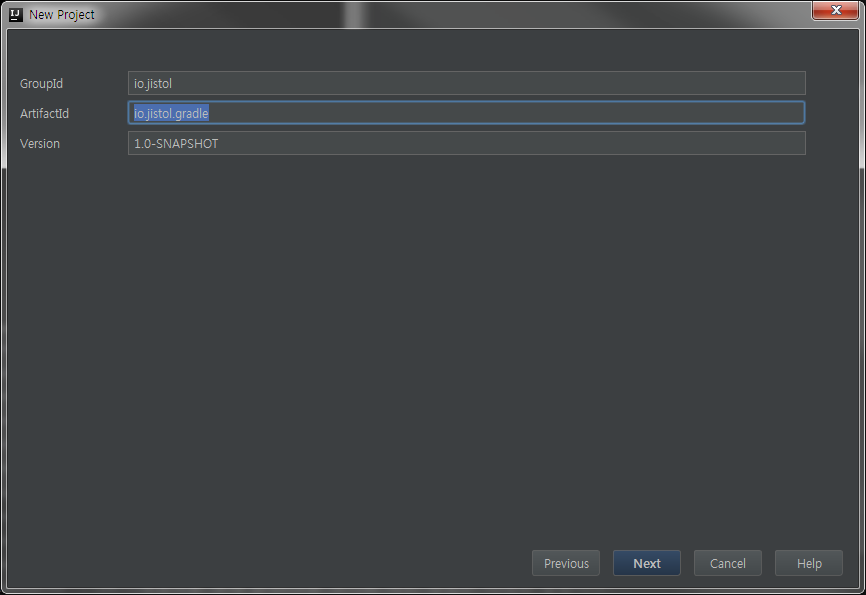
- 필요한 선택항목을 선택 후 Next를 클릭합니다.
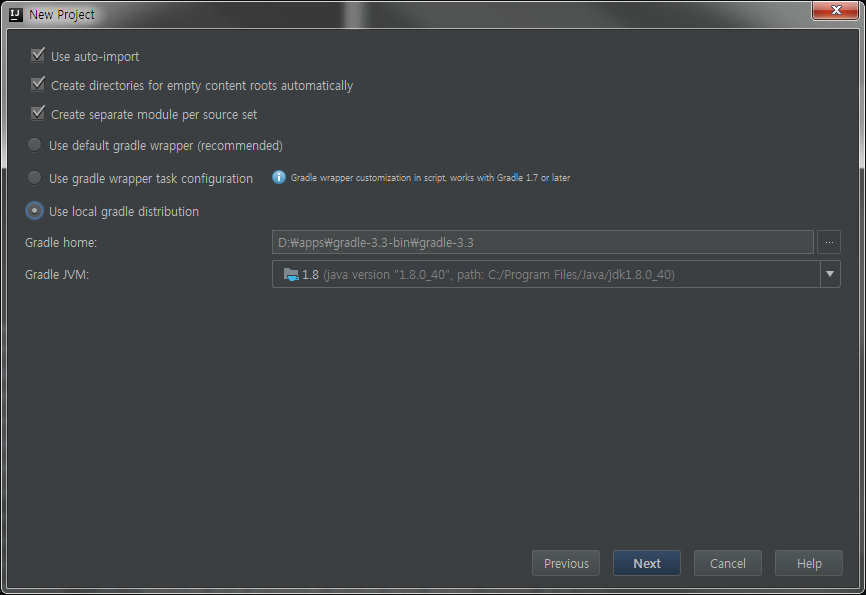
- Use auto-import : dependency 추가시 자동으로 import하는 옵션입니다.
- Create directories for empty content roots automatically : 이 항목을 선택하면 자동으로 src폴더와 하위 구조가 생성됩니다.
- Use default gradle wrapper : Gradle Wrapper를 생성해줍니다.(gradlew.bat …)
- Use gradle wrapper task configuration : Gradle Wrapper를 task를 통해 실행할 수 있도록 스크립트를 만듭니다.

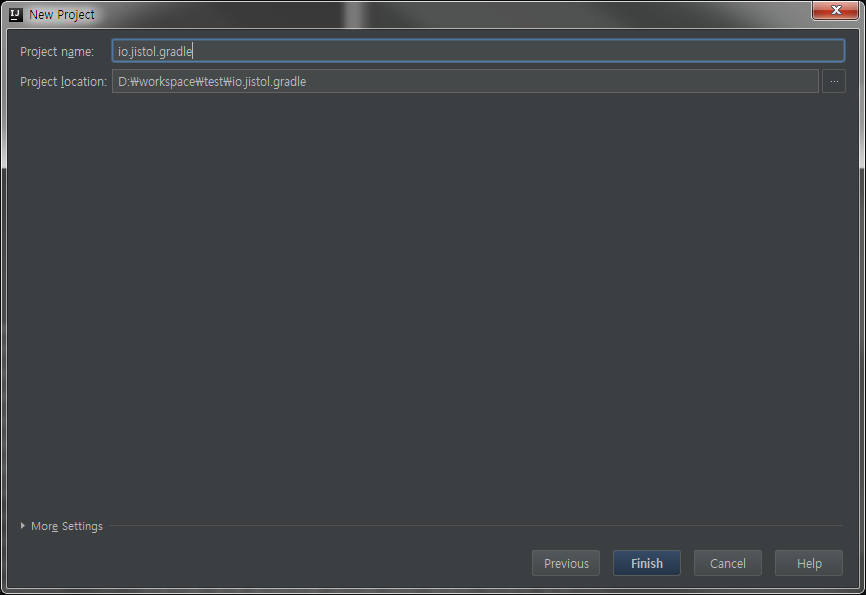
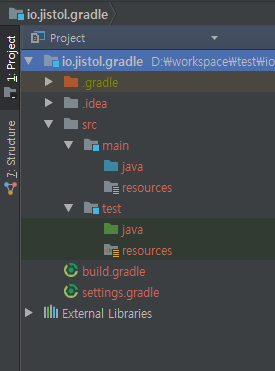
※ 위 커맨드 명령어로 만들때도 같은 구조로 생성됩니다.
그 외에 template을 기반으로 하는 프로젝트 생성 방법은 Gradle 기반의 템플릿 프로젝트 생성을 참고하시기 바랍니다.
참고
권남 - Gradle
Gradle Build - Installation
14 Feb 2017
|
architecture

일반적인 서비스 구성이 위와 같은 상황에서 Client가 늘어날 경우 웹 서버나 DB서버에서 병목현상이 발생할 수 있으며 병목지점별로 해결 방안이 필요합니다.
Web서버 확장
Web서버가 stateless한 구조일 경우 아래와 같이 다수의 Web서버를 두어 부하를 분산 시킬 수 있습니다.
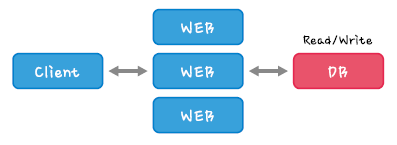
stateful : 서버쪽에 client와 server의 연속된 동작 상태정보를 저장하는 형태
stateless : 서버쪽에 client와 server의 연속된 동작 상태정보를 저장하는 않는 형태
DB 확장
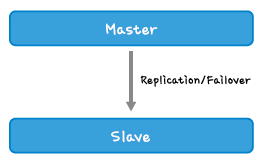
DB구성이 위와 같을 경우 성능향상을 위해 “Scale Up”과 “Scale Out”을 고려해 볼 수 있습니다.
scale up : 장비의 성능을 높여 성능향상
scale out : 장비의 개수를 늘려 성능향상
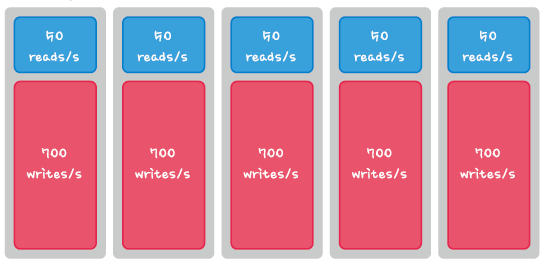
DB Read/Write 분리,분산
대부분의 서비스는 Read가 Write보다 대략 7:3, 8:2비율로 더 많은데 이럴때 Read/Write DB를 분리하면 DB서버의 부하를 줄일 수 있습니다.
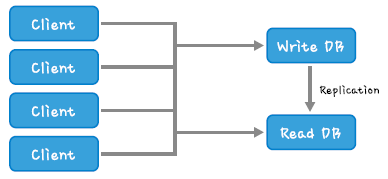
일반적으로 Master DB를 Write, Replication되는 Slave DB를 Read로 사용하는데 기본적으로 4대로 구성합니다.
Master : Write
Slave 1,2,3 : Read
1번서버 장애시 2번서버는 서비스를 하며 3번 서버는 서비스를 중단하고 1번서버 복구를 위한 DB복사를 진행해야합니다.
서비스중인 DB에서 복사시 부하가 가중되므로 여분의 DB가 필요합니다.
Read/Write DB 분기방식으로는 아래와 같은 방법이 있습니다.
- DBProxy 서버를 이용
- 프록시 서버가 쿼리를 분석하여 select시는 Read서버, 그 외엔 Master서버로 분기해줍니다.
- MySql Proxy, MaxScale …
- MySql Replication Jdbc Driver 사용
- Spring LazyConnectionDataSourceProxy + AbstractRoutingDataSource 사용
- Spring에서 Transaction readonly 옵션을 사용하여 분기하는 방법입니다.
- AbstractRoutingDataSource : 여러개의 DateSource를 하나로 묶고 자동 분기처리
- LazyConnectionDataSourceProxy : 트랜잭션 시작되더라도 실제 커넥션이 필요한 경우에 데이터소스에서 커넥션을 반환
Write증가시 파티셔닝
write가 증가하게 되면 Master로부터 Replication을 받기 위해 Slave의 write IO가 증가하게 됩니다.
그렇게 되면 Read Slave를 아무리 늘려도 성능개선이 미미해지는데 이럴때는 Write를 줄이는 파티셔닝을 해야합니다.
-
파티셔닝(Partitioninig)
- 성능,가용성,정비용이성을 목적으로 논리적 데이터 요소들을 다수의 테이블로 쪼개는 행위
- 수직분할(Vertical Partitioninig)
- 테이블의 Column 단위로 파티셔닝하는 방법
- 스키마가 서로 달라집니다.
- 수평분할(Sharding : Horizontal Partitionning)
- 테이블의 Row 단위로 파티셔닝하는 방법
- 스키마는 동일합니다.
-
파티션 방법
- 수동 파티셔닝 : 분석된 테이블 정보를 이용하여 파티션 뷰를 직접 생성
- 파티션 테이블 :
- Range 파티셔닝
- 특정 기간 별로 파티션을 나눔
- 주로 날짜조건 사용
- Hash 파티셔닝
- Hash함수에 적용한 결과값이 같은 레코드별로 나눔
- 변별력 좋고 데이터분포가 고른 컬럼을 선정해야 효과적
- List 파티셔닝
- 사용자에 의해 미리 정해진 그룹핑 기준에 따라 분할
- 결합 파티셔닝
- 자세한 설정방법은 구루비 DB 스터디 - 1. 테이블 파티셔닝을 참조
참고
대용량 서버구축을 위한 Memcached와 Redis
Java 에서 DataBase Replication Master/Slave (write/read) 분기 처리하기
MySQL에서 Replication Driver 사용 시 장애 취약점 리포트
권남 - MySQL JDBC
H2DB - LazyConnectionDataSourceProxy 예제
구루비 DB 스터디 - 1. 테이블 파티셔닝
오라클 성능 고도화 원리와 해법 2 [11-1B]
13 Feb 2017
|
jpa
orm
여러 게시글들을 기반으로 정리해 보았습니다.
ORM(Object-Relational Mapping)이란?
- 객체(Object)와 관계형 데이터베이스(Relational)의 관계 설정을 자동으로 처리해줍니다.
- 실제 데이터와 객체와의 개념적 일치하지 않는 부분을 자동으로 매핑해주는데 ResultSet을 받아 Bean에 열심히 넣어주던것을 대신해주는 것과 비슷하게 생각하면 됩니다.
- 관계형 데이터베이스의 데이터를 객체형 데이터처럼 사용할 수 있습니다.
ORM의 장점
- 데이터베이스 종류에 제약을 최대한 받지 않습니다.(Native Query 사용시 무효)
- 객체 중심으로 설계하기 때문에 좀 더 직관적이고 빠르게 개발할 수 있습니다.
- 객체 지향적 설계로 인해 좀 더 직관적이고 비지니스로직에 집중할 수 있으며 생산성,유지보수성이 향상됩니다.
ORM의 단점
- 모든 기능을 ORM으로만 작성하기에는 쿼리가 복잡해지면 쓰기 어렵습니다.(통계, 데이터분석등…)
- 성능이슈, 몇몇 글에 따르면 ORM을 사용시 느리다는 평이 있습니다.
- SP를 많이 쓰거나 기존 SQL문이 많은 프로그램에는 객체지향의 장점을 활용하기 어렵습니다.
ORM에 적합한 모델
- Entity를 개별적으로 업데이트
- 간헐적으로 Set기반 작업 수행 (ex: 고객 레코드및 주문내역을 개별적으로 업데이트)
ORM에 적합하지 않은 모델
- 많은 수의 레코드를 잦은 빈도로 벌크 업데이트 수행
- 통계, 데이터분석처리(OLAP)
- 이미 작성된 핸드코딩/프로시저를 이용하는 환경(MyBatis를 쓰면 좋다, 다른 ORM도 이런부분을 지원합니다.)
- 순수 SQL문을 쓰는게 더 나을때
참고
ORM (Object Relation Mapping)
ORM 의 장점과 단점
12 Feb 2017
|
vi
vim
linux
v : 비주얼모드(영역지정)
문자단위로 선택영역 지정을 할 수 있습니다.
V : 라인단위 비주얼모드(영역지정)
라인단위로 선택영역 지정을 할 수 있습니다.
y : 복사
문자단위 또는 선택영역을 복사하여 버퍼에 저장합니다.
복사한 문자는 다른 버퍼를 사용하는 명령어(ex:x,d,dd,p …)를 사용할 경우 없어집니다.
Y : 라인단위 복사
한 줄을 복사하여 버퍼에 저장합니다.
복사한 문자는 다른 버퍼를 사용하는 명령어(ex:x,d,dd,p …)를 사용할 경우 없어집니다.
p : 붙여넣기(현재 커서 앞)
버퍼의 내용을 현재 커서 앞에 붙여넣습니다.
P : 붙여넣기(현재 커서 뒤)
버퍼의 내용을 현재 커서 뒤에 붙여넣습니다.
u : 실행취소
이전 실행한 내용을 취소합니다.
ctrl + r : 다시실행
실행 취소한 내용을 다시 실행합니다.
11 Feb 2017
|
jpa
spring
springboot
springdata
일반적으로 JPA에서 Sort기능을 사용하기 위해서 아래와 같이 메서드명에 OrderBy를 붙여 사용합니다.
public Page<T> findAllByNameOrderByCreatedDateDesc();
이와 같이 만드는 경우 일반적인 목록조회 페이지에서 다수의 정렬기능(ex:이름순,날짜순,날짜역순…)을 필요로 할 경우 위와 같은 메소드를 정렬 방식 개수대로 만들어야 하는 단점이 있습니다.
이 때 사용하기 좋은것이 Sort클래스입니다.
Controller에 아래와 같이 인자값으로 등록만 하면 알아서 정렬정보가 세팅됩니다.
@Controller
public List<T> list(Sort sort)
{
List<T> tList = jpaRepository.findAll(sort);
return tList;
}
파라메터 형식은 아래와 같이 넘길 수 있습니다.
[이름으로 정렬]
/path?sort=name,asc
[이름 역순으로 정렬]
/path?sort=name,desc
[이름으로 정렬 + ID로 정렬]
/path?sort=name,id
[이름으로 정렬 + ID 역순으로 정렬]
/path?sort=name,asc&sort=id,desc
파라메터에서 전달받은 정렬조건외에 추가적으로 정렬조건을 추가하고 싶을 경우 아래와 같이 and메소드를 이용하여 추가적으로 정렬조건을 넣을수 있습니다.
@Controller
public List<T> list(Sort sort)
{
sort = sort.and(new Sort(Sort.Direction.DESC, "count"))
List<T> tList = jpaRepository.findAll(sort);
return tList;
}
보통 목록에서 정렬은 paging과 같이 하는 경우가 많은데 아래와 같이 Pageable을 인자값으로 받으면 자동적으로 정렬값이 추가됩니다.
@Controller
public List<T> list(Pageable pageable)
{
List<T> tList = jpaRepository.findAll(pageable);
return tList;
}
참고 : Spring Data JPA Tutorial: Sorting
