SpringBoot를 이용하여 간단한 POC를 자주 진행하곤 했었는데 매번 Maven/Gradle 설정하고 프로젝트 구조 맞추고 하기가 번거로워 샘플 프로젝트를 하나 만들어두고 사용하고 있었습니다.
그러던 와중에 Spring Initializr를 알게 되어 사용해봤는데 완전 신세계였습니다.
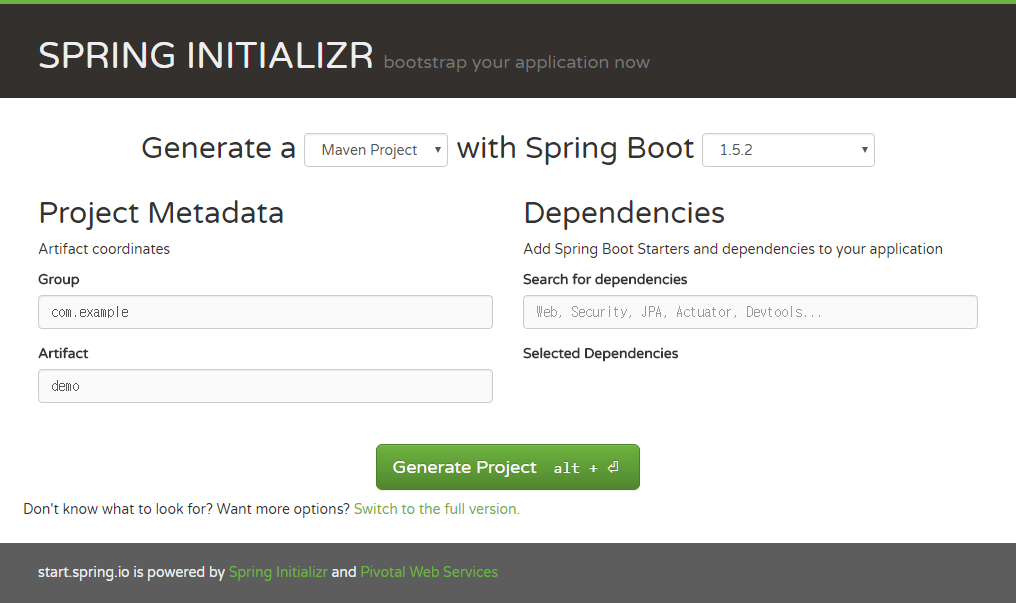
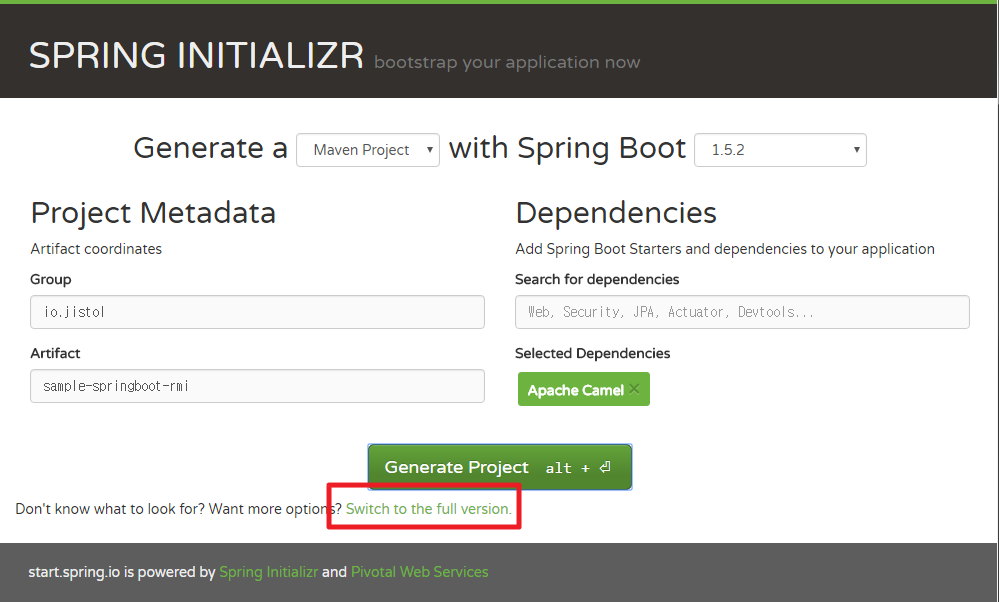
초기화면은 아래와 같습니다.
빌드 툴은 Maven과 Gradle중에 선택할 수 있습니다.
사용할 SpringBoot Version을 선택하고,
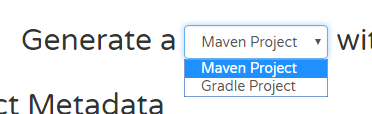
Group/Artifact를 지정하고,
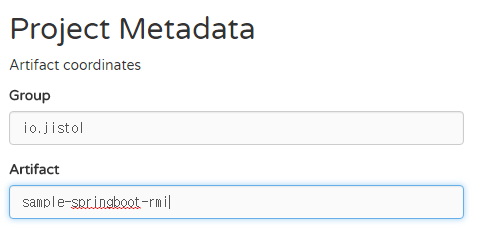
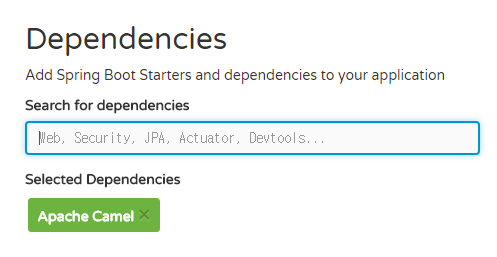
사용할 Dependencies를 추가로 선택할 수 있습니다. 키워드 자동완성식 검색을 제공하여 검색하기 편하네요 :)
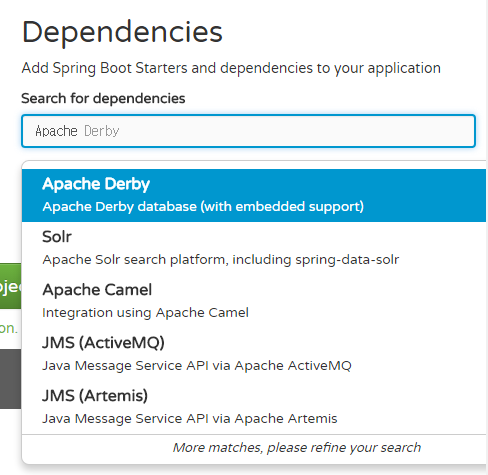
선택한 Dependencies는 아래와 같이 표시됩니다.
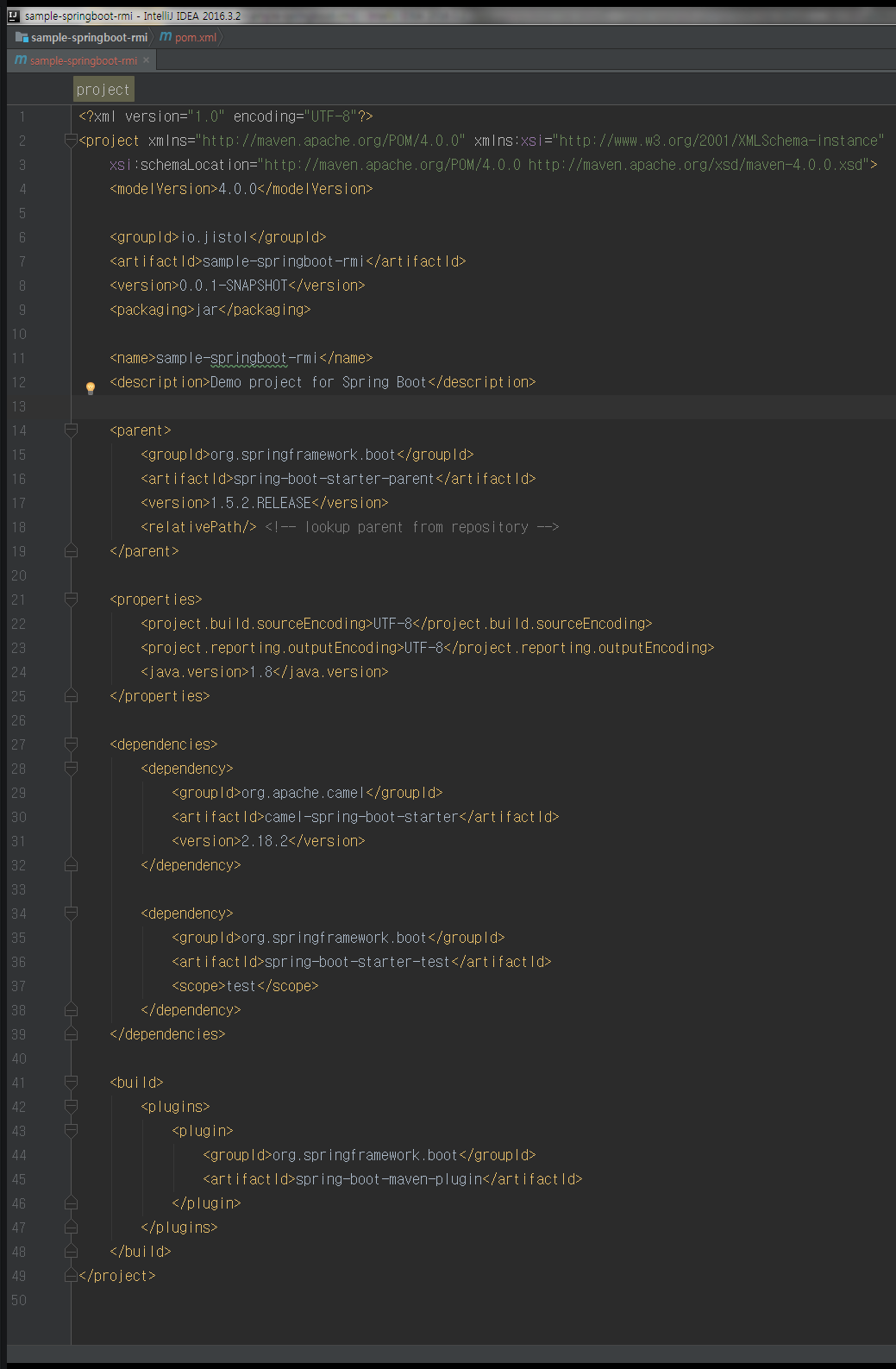
“Generate Project”버튼을 클릭하여 zip파일로 다운을 받고 압축을 풀어 pom.xml파일을 확인해보면 우아하게 Maven 설정이 되어있습니다.
Linux 환경에서 sudo는 root계정으로 로그인하지 않은 상태로 sudoers의 설정에 따라 특정 명령을 사용할 수 있도록 해줍니다.
이에 따라 서버 관리자들이 root계정 사용을 최소화 하고 sudo를 이용하여 작업함으로써 누가 어떤 커맨드를 사용했는지 추적이 가능해집니다.
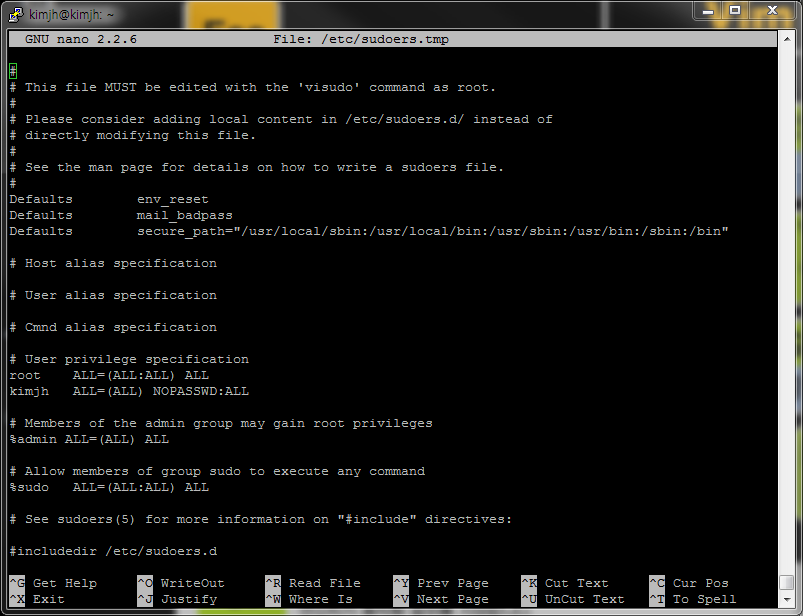
/etc/sudoers 에 각 사용자별 사용 가능한 설정이 포함되어 있으나 vi로 직접 수정하기 보다는 visudo 명령으로 수정하기를 권장합니다.
$ visudo
사용자 설정
특정 사용자에게 명령 권한을 설정할 때는 아래와 같이 설정 할 수 있습니다.
(user) (host)=(runUser[:runGroup]) [option:](command)
# User privilege specification
root ALL=(ALL:ALL) ALL
# kimjh 사용자는 password입력없이 모든 명령을 실행 할 수 있습니다.
kimjh ALL=(ALL) NOPASSWD:ALL
# docker 계정은 localhost에서 vi명령어를 admin그룹의 kimjh 계정의 권한으로 실행할 수 있습니다.
docker localhost=(kimjh:admin) /usr/bin/vi
그룹 설정
특정 그룹에 명령 권한을 설정할 때는 아래와 같이 설정 할 수 있습니다.
%(group) (host)=(runUser[:runGroup]) [option:](command)
# Members of the admin group may gain root privileges
%admin ALL=(ALL) ALL
# docker 그룹에 속한 계정은 localhost에서 vi명령어를 admin그룹의 kimjh 계정의 권한으로 실행할 수 있습니다.
%docker localhost=(kimjh:admin) /usr/bin/vi
Alias 설정
Alias는 특정 호스트나 유저, 커맨드등을 하나로 묶어 Alias형태로 제공하고 아래와 같은 형식으로 정의합니다.
또한 user정보에 특수문자가 포함되거나 공백이 포함될 경우 더블쿼터(“)로 묶어 사용하거나 백슬래쉬()를 이용할 수 있습니다.
Runas_Alias
어떤 계정의 권한으로 명령을 실행 할 지에 대한 Alias설정을 지정합니다.
아래 예제와 같이 설정 된 상태에서 docker계정으로 vi명령을 실행 할 경우 Runas_Alias에 설정된 계정으로 실행되게 됩니다.
[/etc/sudoers]
# User privilege specification
docker ALL=(R_ROOT) NOPASSWD:/usr/bin/vi
docker@kimjh:$ sudo vi test
docker@kimjh:$ ls -atrl test
-rw-r--r-- 1 root root 22 2월 24 11:28 test
문법은 User_Alias와 동일하게 사용합니다.
Host_Alias
특정 실행권한에 대한 host를 Alias로 설정하여 허용되지 않은 사용자가 원격 접속하여 실행하는 것을 방지하기 위해 지정합니다.
아래 예제와 같이 설정 된 상태에서 docker계정은 211.63.24.9번 IP나 kimjh 호스트 서버에서만 vi명령을 실행 할 수 있습니다.
[/etc/sudoers]
# Host alias specification
Host_Alias H_LOCAL = 211.63.24.9, kimjh
# User privilege specification
docker H_LOCAL=(ALL) NOPASSWD:/usr/bin/vi
Cmnd_Alias
실행 명령어를 Alias로 지정할 수 있습니다.
아래 예제와 같이 설정 된 상태에서 docker계정은 vi명령과 vim명령을 실행 할 수 있습니다.
# Cmnd alias specification
Cmnd_Alias CMD_VIM = /usr/bin/vi, /usr/bin/vim
# User privilege specification
docker ALL=(ALL:ALL) CMD_VIM
출근길에 TED영상을 보다가 3분채 안되는 이 영상을 보게 되었습니다.
30일이면 나 자신을 바꾸기에 충분한 시간이라는 말에 홀려 가볍게 해 볼 수 있는게 무엇이 있을까 생각하다가 근래 만들었던 GitHub Page에 기술 포스팅을 해보는 것으로 정했습니다. 지금 생각해보면 절대 가볍게 할 수 있는 일은 아니였습니다.
고비
첫 날은 기존부터 개념 정리차 공부하고 있던 Agile관련 포스팅을 진행했습니다.
글 쓰는게 익숙하지 않았지만 그래도 공부했던 내용들이 있어 나름 어렵지 않게 포스팅 했습니다. 하지만 고비는 그 이후였습니다.
아무 글이나 쓰는게 아닌 기술 포스팅을 하려니 먼저 공부를 해야했고 그 내용을 정리해서 글을 올려야 했습니다.
에버노트에 쓰는건 나만 알아보게 대충 적어놓으면 되는 것이였으나 포스팅은 인터넷에 검색되어 남도 보게 되는 글이기 때문에 몇 번이고 사실 검증을 해야했고 두서 없이 필요한 글만 올릴 수도 없었습니다. 게다가 코딩은 익숙했지만 정리해서 포스팅하는것은 익숙하지 않아 생각보다 많은 시간이 걸렸습니다.(이 때문에 야근도 하게 되었죠…)
한 두번은 쉬워 보이는 일도 매일 쭉 한다고 정해놓고 하게 되니 절대 쉬운게 아니였습니다. 특히 “매일”이라는 조건이 가장 어려웠습니다.
변화
“공부-일-포스팅”을 동시에 하기 위해 매일 1시간, 최소 30분 이상 일찍 출근해서 공부했으며 출퇴근 길에도 항상 윈탭으로 기술문서를 읽고 검색하게 되었습니다.
일하는 도중에도 “이건 오늘 정리해서 포스팅하자.”하는 부분을 다시 공부하고 검증하게 되었으며 일이 바쁠땐 집에가서 새벽까지 문서를 쓰기도 했습니다.
매일 글을 쓰다보니 처음보다 생각의 정리나 글 쓰는 요령이 붙어 속도가 나기 시작하고 기술에 대해서도 필요한 부분만 확인하는것이 아니라 해당 기술에 대한 다른 부분까지 같이 검토하게 되는 습관이 생겼습니다.
출퇴근길에 의미없이 하던 인터넷 서핑도 자기 개발에 투자하게 되었으며, 에버노트에 간단히 메모해두고 잊혀졌던 했던 잡 지식들도 차츰 정리할 수 있었습니다.
결과
이 포스팅을 끝으로 30일간의 도전은 성공하였으며 오늘 저녁은 아름답게 치맥을 먹으며 마무리 할 수 있을것 같습니다.
30일간의 도전으로 얻었다고 생각드는 것은 아래와 같습니다.
글쓰기에 대한 부담감이 없어지고 글 쓰는 실력이 늘었습니다.
공부했거나 사용한 기술에 대해 한번 더 생각하고 정리하는 습관이 들었습니다.
매일 공부하는 습관을 들이고 발전적인 삶을 사는 것에 대한 보람을 느꼈습니다.
기술에 대해 누군가와 논의할 때 좀 더 생각을 정리하고 더 잘 표현하게 된 것 같습니다.
부작용
“매일”이라는 압박 때문에 아래와 같은 부작용이 있었습니다.
공부한 내용을 포스팅하지 않고 포스팅을 하기 위한 공부를 할 때가 있었습니다.(주객전도…)
하루에 하나씩 올려야 하기 때문에 깊이 있는 내용을 쓰기가 어려웠습니다.
정말 공부를 할 수 없는 상황이 됬을때를 대비해 미리 포스팅을 축적하기도 했습니다.
회고
이번 도전을 하면서 최근 한달은 정말 열심히 공부했던것 같습니다. 흡사 시험전날 벼락치기를 30일동안 한 기분같기도 합니다.
일이 바빠져서 포기하려 할 때도 있었으나 와이프가 옆에서 응원해주어 포기하지 않고 끝까지 해 낼수 있었고 작은 것 하나를 도전했는데 정말 큰 결실을 맺은것 같습니다.
이 도전은 끝났지만 30일동안의 변화를 경험했기 때문에 다른 도전도 계획해보려합니다.
이 포스팅을 보시는 분들도 작은것 하나라도 도전해보시면 나 자신을 변화 시키는데 큰 도움이 될 거라 생각합니다.
publicenumEnumCode{L("대형"),// name : L, ordinal : 0M("중형"),// name : M, ordinal : 1S("소형");// name : S, ordinal : 2privateStringdescription;StoreTypeCode(Stringdescription){this.description=description;}publicStringgetDescription(){returndescription;}}
Entity객체를 통해 테이블 컬럼에 ‘L’, ‘M’, ‘S’값을 저장할 예정이며 아래와 같이 설정하였습니다.