SSM(simple-spring-memcached) MultiCache 사용하기 (@ReadThroughMultiCache, @UpdateMultiCache, @InvalidateMultiCache)
27 Nov 2018 | simplespringmemcached ssm memcached google cache readthroughmulticache“Spring + Memcached” 조합일때 simple-spring-memcached(이하 ssm)이 많이 사용되는데 인터넷에 보면 대부분 @ReadThroughSingleCache나 @ReadThroughAssignCache에 대한 설명이나 예제는 많은데 @ReadThroughMultiCache관련된 예제는 유독 찾아보기 힘들었습니다.
심지어 공식 가이드에도 간략하게만 써있어서 실제 동작 방식에 대해 알아보기 위해 xmemcached기반으로 직접 테스트 프로젝트를 만들어보고 테스트 해본 내용에 대한 포스팅입니다.
Basic
아래 코드는 기본적인 사용 방법입니다.
@ReadThroughMultiCache
public List<Integer> randomMulti(@ParameterValueKeyProvider List<Integer> nums) {
......
}
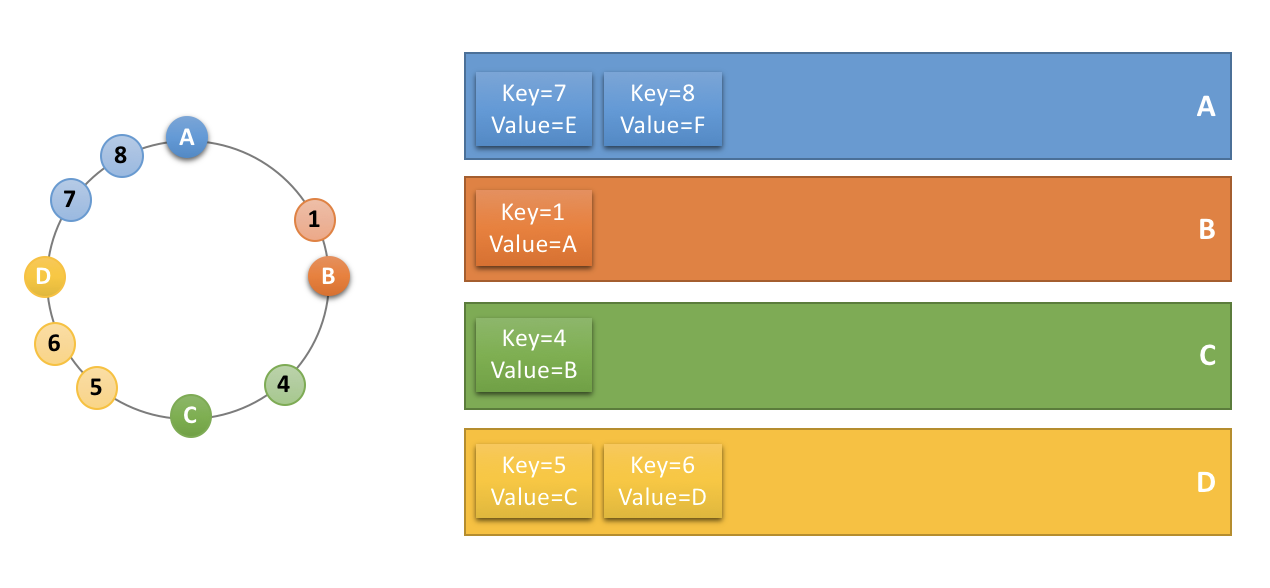
하나의 java.util.List인자값을 포함하고 java.util.List 또는 java.util.List를 상속한 클래스를 리턴하는 메소드에만 적용할 수 있습니다.
위와 같이 적용시 ssm은 자동으로 인자값의 List와 결과값의 List를 매핑하여 분산하여 캐시키를 저장하게 됩니다.
위 Java코드를 기반으로 실행시 인자값과 반환값이 아래와 같을 경우 실제 캐시에 저장되는 예시입니다.
// argument : List(1,2,3,4,5)
// returnValue : List(11,22,33,44,55)
stats cachedump 5 100
ITEM local:TMON::COMMON:randomMulti:1 [135 b; 1543323568 s] // value is 11
ITEM local:TMON::COMMON:randomMulti:2 [145 b; 1543323568 s] // value is 22
ITEM local:TMON::COMMON:randomMulti:3 [155 b; 1543323568 s] // value is 33
ITEM local:TMON::COMMON:randomMulti:4 [165 b; 1543323568 s] // value is 44
ITEM local:TMON::COMMON:randomMulti:5 [175 b; 1543323568 s] // value is 55
END
@ReadThroughSingleCache의 경우 “1,2,3,4,5” 전체를 키 값으로 사용하지만 @ReadThroughMultiCache의 경우 List의 각 키 값을 분산 저장하고 재활용 합니다.
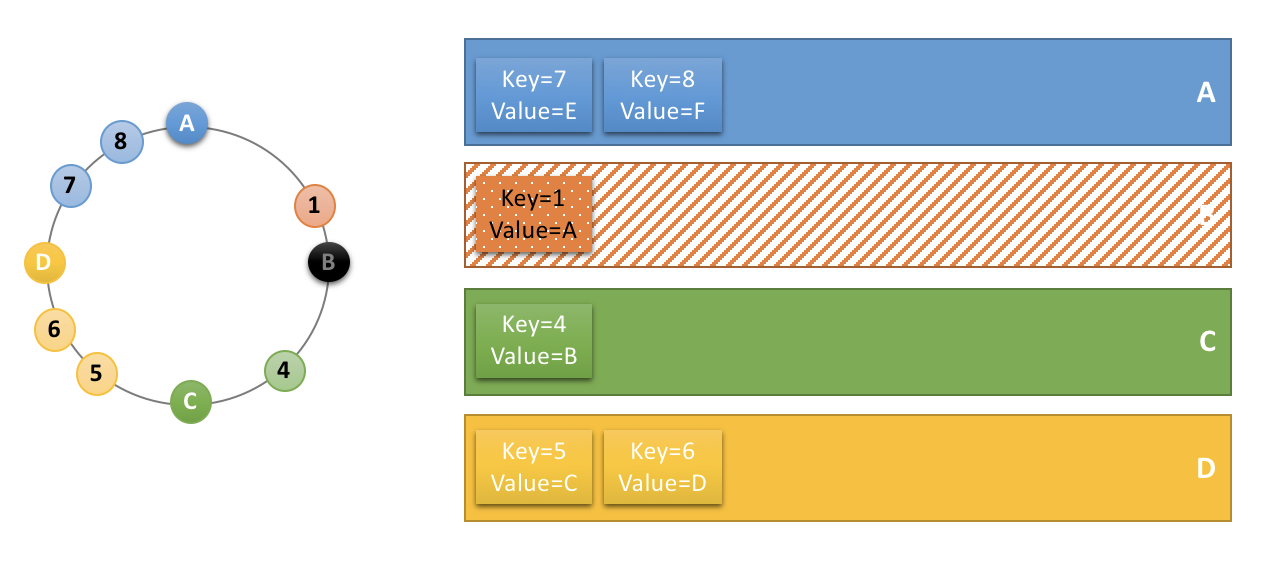
위와 같이 캐시가 저장된 상태에서 다시 아래와 같이 실행할 경우 기존 캐시된 값은 그대로 사용하고 캐시가 없는 부분만 다시 캐시에 저장합니다.
// argument : List(2,4,6,8)
// returnValue : List(22,44,66,88)
stats cachedump 5 100
ITEM local:TMON::COMMON:randomMulti:1 [135 b; 1543323568 s]
ITEM local:TMON::COMMON:randomMulti:2 [145 b; 1543323568 s] // use existing cache
ITEM local:TMON::COMMON:randomMulti:3 [155 b; 1543323568 s]
ITEM local:TMON::COMMON:randomMulti:4 [165 b; 1543323568 s] // use existing cache
ITEM local:TMON::COMMON:randomMulti:5 [175 b; 1543323568 s]
ITEM local:TMON::COMMON:randomMulti:6 [185 b; 1543324016 s] // new cache
ITEM local:TMON::COMMON:randomMulti:8 [205 b; 1543324016 s] // new cache
END
새로 캐시를 저장하는 것이 아니기 때문에 expiration 설정을 했을 경우 1~5번 캐시는 동시에 삭제되고 6,8번 캐시는 이후 삭제됩니다.
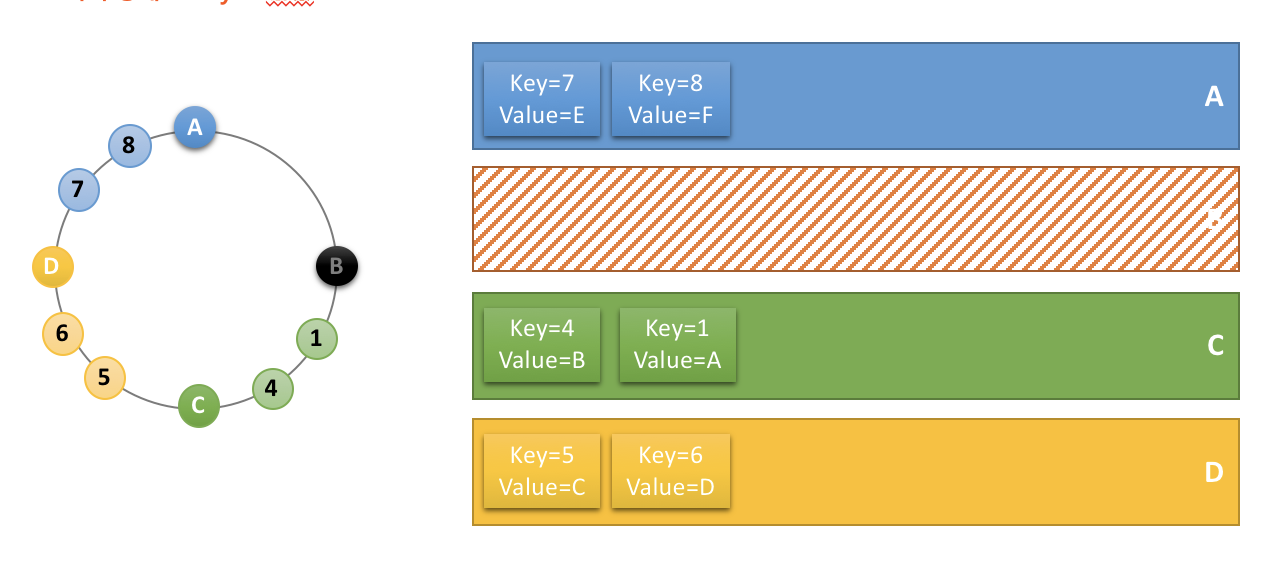
위 메서드를 디버깅해보면 애초에 인자값에 캐시 데이터가 없는 값만 추려 전달하는것을 볼 수 있습니다.
// execute 1 => argument = List(1,2,3,4,5)
@ReadThroughMultiCache
public List<Integer> randomMulti(@ParameterValueKeyProvider List<Integer> nums) {
// nums = List(1,2,3,4,5)
......
}
// execute 2 => argument = List(2,4,6,8)
@ReadThroughMultiCache
public List<Integer> randomMulti(@ParameterValueKeyProvider List<Integer> nums) {
// nums = List(6,8)
......
}
이미 캐싱 되 있는 값을 Update 하기 위해서는 @UpdateMultiCache를 이용 할 수 있습니다.
@UpdateMultiCache
public void updateMulti(@ParameterValueKeyProvider List<Integer> multi, @ParameterDataUpdateContent List<List<Integer>> content) {
......
}
위 예제와 같이 @ParameterDataUpdateContent어노테이션을 사용하여 저장할 값을 직접 주입할 수 있으며,
@ReturnDataUpdateContent
@UpdateMultiCache
public List<Integer> updateMulti(@ParameterValueKeyProvider List<Integer> multi) {
......
}
@ReturnDataUpdateContent어노테이션을 사용하여 반환값을 저장할 수도 있습니다.
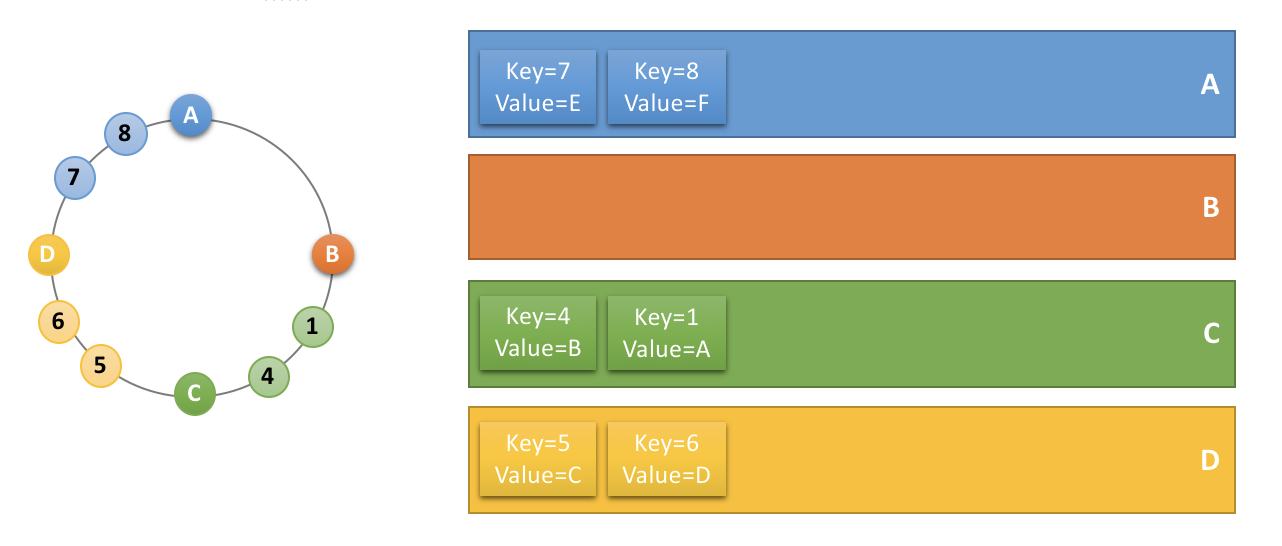
캐시를 만료 시킬때는 @InvalidateMultiCache어노테이션을 사용합니다.
@InvalidateMultiCache
public void invalidateMulti(@ParameterValueKeyProvider List<Integer> multi) {
......
}
Caution - Argument
@ReadThroughMultiCache는 반드시 하나의 java.util.List 인자값을 포함해야합니다.
@ReadThroughMultiCache
public List<Integer> randomMulti(@ParameterValueKeyProvider Integer multi) {
......
}
위와 같이 인자값이 잘못됬을 경우 정상실행 되나 캐싱되지 않으며 아래와 같은 오류 메시지가 발생합니다.
[2018-11-27 22:13:46] [WARN ] c.g.c.s.a.CacheAdvice.warn[55] Caching on execution(XXXService.randomMulti(..)) aborted due to an error.
com.google.code.ssm.aop.support.InvalidAnnotationException: No one parameter objects found at dataIndexes [[0]] is not a [java.util.List]. [public java.util.List test.service.XXXService.randomMulti(java.lang.Integer)] does not fulfill the requirements.
java.util.List타입 대신 Array를 사용하더라도 동일한 오류를 발생시킵니다.
@ReadThroughMultiCache
public List<Integer> randomMulti(@ParameterValueKeyProvider Integer[] multi) {
......
}
[2018-11-27 22:16:23] [WARN ] c.g.c.s.a.CacheAdvice.warn[55] Caching on execution(XXXService.randomMulti(..)) aborted due to an error.
com.google.code.ssm.aop.support.InvalidAnnotationException: No one parameter objects found at dataIndexes [[0]] is not a [java.util.List]. [public java.util.List test.service.XXXService.randomMulti(java.lang.Integer[])] does not fulfill the requirements.
java.util.List타입 인자값이 2개 이상일 경우에도 오류를 발생시킵니다.
@ReadThroughMultiCache
public List<Integer> randomMulti(@ParameterValueKeyProvider List<Integer> multi, @ParameterValueKeyProvider(order = 1) List<Integer> multi2) {
......
}
[2018-11-27 22:19:18] [WARN ] c.g.c.s.a.CacheAdvice.warn[55] Caching on execution(XXXService.randomMulti(..)) aborted due to an error.
com.google.code.ssm.aop.support.InvalidAnnotationException: There are more than one method's parameter annotated by @ParameterValueKeyProvider that is list public java.util.List test.service.XXXService.randomMulti(java.util.List,java.util.List)
하지만 java.util.List타입 인자값이 1개라면 아래와 같이 다른 키 값이 추가 되더라도 정상적으로 캐시를 저장합니다.
@ReadThroughMultiCache
public List<List<Integer>> randomMulti(@ParameterValueKeyProvider Integer fixSize, @ParameterValueKeyProvider(order = 1) List<Integer> multi) {
......
}
// argument : fixSize = 2 , multi = List(1,2,3)
stats cachedump 6 100
ITEM local:TMON::COMMON:randomMulti:2,3 [145 b; 1543325621 s]
ITEM local:TMON::COMMON:randomMulti:2,2 [145 b; 1543325621 s]
ITEM local:TMON::COMMON:randomMulti:2,1 [145 b; 1543325621 s]
END
순서를 반대로 해도 정상적으로 저장합니다.
@ReadThroughMultiCache
public List<List<Integer>> randomMulti(@ParameterValueKeyProvider List<Integer> multi, @ParameterValueKeyProvider(order = 1) Integer fixSize) {
......
}
// argument : multi = List(1,2,3), fixSize = 2
stats cachedump 6 100
ITEM local:TMON::COMMON:randomMulti:3,2 [145 b; 1543325799 s]
ITEM local:TMON::COMMON:randomMulti:2,2 [145 b; 1543325799 s]
ITEM local:TMON::COMMON:randomMulti:1,2 [145 b; 1543325799 s]
END
Caution - Return Data
@ReadThroughMultiCache는 반드시 java.util.List타입의 반환값을 가져야합니다.
반환값이 java.util.List이 아닐 경우 메소드 자체는 정상 동작하지만 아래와 같이 오류 메시지를 반환하며 캐시는 저장되지 않습니다.
@ReadThroughMultiCache
public Integer randomMultiFindOne(@ParameterValueKeyProvider List<Integer> multi) {
......
}
[2018-11-27 22:30:32] [WARN ] c.g.c.s.a.CacheAdvice.warn[55] Caching on execution(XXXService.randomMultiFindOne(..)) aborted due to an error.
com.google.code.ssm.aop.support.InvalidAnnotationException: The annotation [com.google.code.ssm.api.ReadThroughMultiCache] is only valid on a method that returns a [java.util.List] or its subclass. [public java.lang.Integer test.service.XXXService.randomMultiFindOne(java.util.List)] does not fulfill this requirement.
인자값과 반환값을 쌍으로 캐시에 저장하기 때문에 인자값의 size와 반환값의 size는 동일해야 합니다.
인자값보다 반환값의 size가 더 많거나 적을 경우 아래와 같은 오류 메시지를 남기고 캐시는 저장되지 않습니다.
[2018-11-27 22:38:24] [WARN ] c.g.c.s.a.ReadThroughMultiCacheAdvice.generateByKeysProviders[166] Did not receive a correlated amount of data from the target method: %s. Result list will be unsorted and won't respect the order of the keys passed in argument.
인자값과 반환값의 size가 같을 경우 캐시를 분할하여 저장하게 되는데 인자값과 반환값의 같은 index끼리 저장하게 되기 때문에 반환값의 순서가 중요합니다.
순서가 다를 경우 오류도 없이 캐시가 엉망으로 저장될 수 있습니다.
Conclusion
SSM은 분명 편하게 “Spring + Memcached” 조합을 사용 할 수 있게 해주지만 간단한 만큼 인적오류로 인한 실수를 범할 수 있으며 오류 로그 역시 warn 레벨로 남기기 때문에 잘못을 인지하지 못하고 사용하는 경우가 많습니다.
특히 @ReadThroughMultiCache의 경우 위에서 알아본 바와 같이 개발자가 실수할 수 있는 여지가 많기 때문에 더더욱 신중하게 사용해야 하지만 자동으로 분할하여 캐시를 저장하며 실행시 알아서 캐시되 있지 않은 값만 따로 실행해주기 때문에 분명 매력적인 부분이 존재합니다.