
대용량 처리를 위한 서비스 구성
14 Feb 2017 | architecture
일반적인 서비스 구성이 위와 같은 상황에서 Client가 늘어날 경우 웹 서버나 DB서버에서 병목현상이 발생할 수 있으며 병목지점별로 해결 방안이 필요합니다.
Web서버 확장
Web서버가 stateless한 구조일 경우 아래와 같이 다수의 Web서버를 두어 부하를 분산 시킬 수 있습니다.
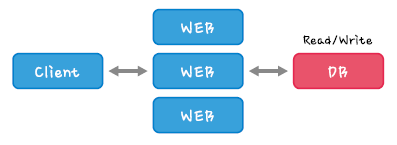
stateful : 서버쪽에 client와 server의 연속된 동작 상태정보를 저장하는 형태
stateless : 서버쪽에 client와 server의 연속된 동작 상태정보를 저장하는 않는 형태
DB 확장
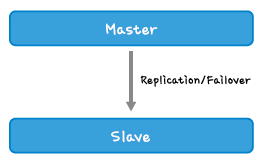
DB구성이 위와 같을 경우 성능향상을 위해 “Scale Up”과 “Scale Out”을 고려해 볼 수 있습니다.
scale up : 장비의 성능을 높여 성능향상
scale out : 장비의 개수를 늘려 성능향상
DB Read/Write 분리,분산
대부분의 서비스는 Read가 Write보다 대략 7:3, 8:2비율로 더 많은데 이럴때 Read/Write DB를 분리하면 DB서버의 부하를 줄일 수 있습니다.
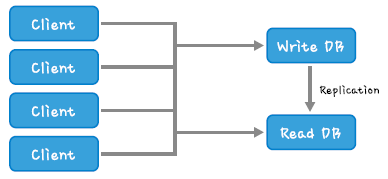
일반적으로 Master DB를 Write, Replication되는 Slave DB를 Read로 사용하는데 기본적으로 4대로 구성합니다.
Master : Write
Slave 1,2,3 : Read
1번서버 장애시 2번서버는 서비스를 하며 3번 서버는 서비스를 중단하고 1번서버 복구를 위한 DB복사를 진행해야합니다.
서비스중인 DB에서 복사시 부하가 가중되므로 여분의 DB가 필요합니다.
-
Eventual Consistency
Master의 내용을 Slave로 Replication하는 과정은 동기/비동기 방식이 있는데 비동기식일 경우 데이터 불일치가 발생할 수 있습니다.
불일치하더라도 시간이 지나면 데이터가 같아지는데 이를 “Eventual Consistency”라고 합니다.
데이터 일관성이 중요한 경우 Read를 분리할때 위와 같은 문제점을 인지해야합니다.
Read/Write DB 분기방식으로는 아래와 같은 방법이 있습니다.
- DBProxy 서버를 이용
- 프록시 서버가 쿼리를 분석하여 select시는 Read서버, 그 외엔 Master서버로 분기해줍니다.
- MySql Proxy, MaxScale …
- MySql Replication Jdbc Driver 사용
- Jdbc Driver상에서 내부적으로 readonly 옵션에 따라 Master/Slave장비를 선택해줍니다.
- “MySQL에서ReplicationDriver사용시장애취약점리포트-기능테스트” 포스팅을 보시면 취약점에 대한 테스트 결과및 Oracle측의 답변이 있습니다.(2012년도 포스팅이니 현재는 해결이 됬는지 모르겠습니다.)
- “권남 - MySQL JDBC“에도 역시 여러가지 문제점들이 도출되어 있습니다.
- 결론적으로 사용 안하는 쪽이 나을듯 합니다.
- Spring LazyConnectionDataSourceProxy + AbstractRoutingDataSource 사용
- Spring에서 Transaction readonly 옵션을 사용하여 분기하는 방법입니다.
- AbstractRoutingDataSource : 여러개의 DateSource를 하나로 묶고 자동 분기처리
- LazyConnectionDataSourceProxy : 트랜잭션 시작되더라도 실제 커넥션이 필요한 경우에 데이터소스에서 커넥션을 반환
Write증가시 파티셔닝
write가 증가하게 되면 Master로부터 Replication을 받기 위해 Slave의 write IO가 증가하게 됩니다.
그렇게 되면 Read Slave를 아무리 늘려도 성능개선이 미미해지는데 이럴때는 Write를 줄이는 파티셔닝을 해야합니다.
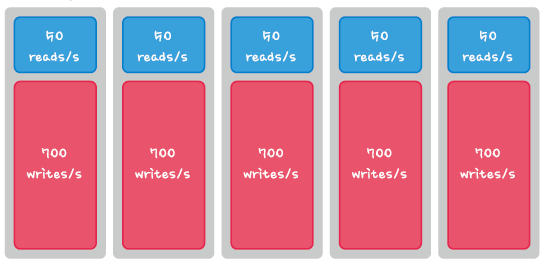
-
파티셔닝(Partitioninig)
- 성능,가용성,정비용이성을 목적으로 논리적 데이터 요소들을 다수의 테이블로 쪼개는 행위
- 수직분할(Vertical Partitioninig)
- 테이블의 Column 단위로 파티셔닝하는 방법
- 스키마가 서로 달라집니다.
- 수평분할(Sharding : Horizontal Partitionning)
- 테이블의 Row 단위로 파티셔닝하는 방법
- 스키마는 동일합니다.
-
파티션 방법
- 수동 파티셔닝 : 분석된 테이블 정보를 이용하여 파티션 뷰를 직접 생성
- 파티션 테이블 :
- Range 파티셔닝
- 특정 기간 별로 파티션을 나눔
- 주로 날짜조건 사용
- Hash 파티셔닝
- Hash함수에 적용한 결과값이 같은 레코드별로 나눔
- 변별력 좋고 데이터분포가 고른 컬럼을 선정해야 효과적
- List 파티셔닝
- 사용자에 의해 미리 정해진 그룹핑 기준에 따라 분할
- 결합 파티셔닝
- 위 파티션 기법을 조합하여 사용
- Range 파티셔닝
- 자세한 설정방법은 구루비 DB 스터디 - 1. 테이블 파티셔닝을 참조
참고
대용량 서버구축을 위한 Memcached와 Redis
Java 에서 DataBase Replication Master/Slave (write/read) 분기 처리하기
MySQL에서 Replication Driver 사용 시 장애 취약점 리포트
권남 - MySQL JDBC
H2DB - LazyConnectionDataSourceProxy 예제
구루비 DB 스터디 - 1. 테이블 파티셔닝
오라클 성능 고도화 원리와 해법 2 [11-1B]
Comments